Problem Overview
- We are given an array of strings
strs - Our goal is to group the anagrams together and return an array of array of strings
- All strings are in lowercase English letters
Example
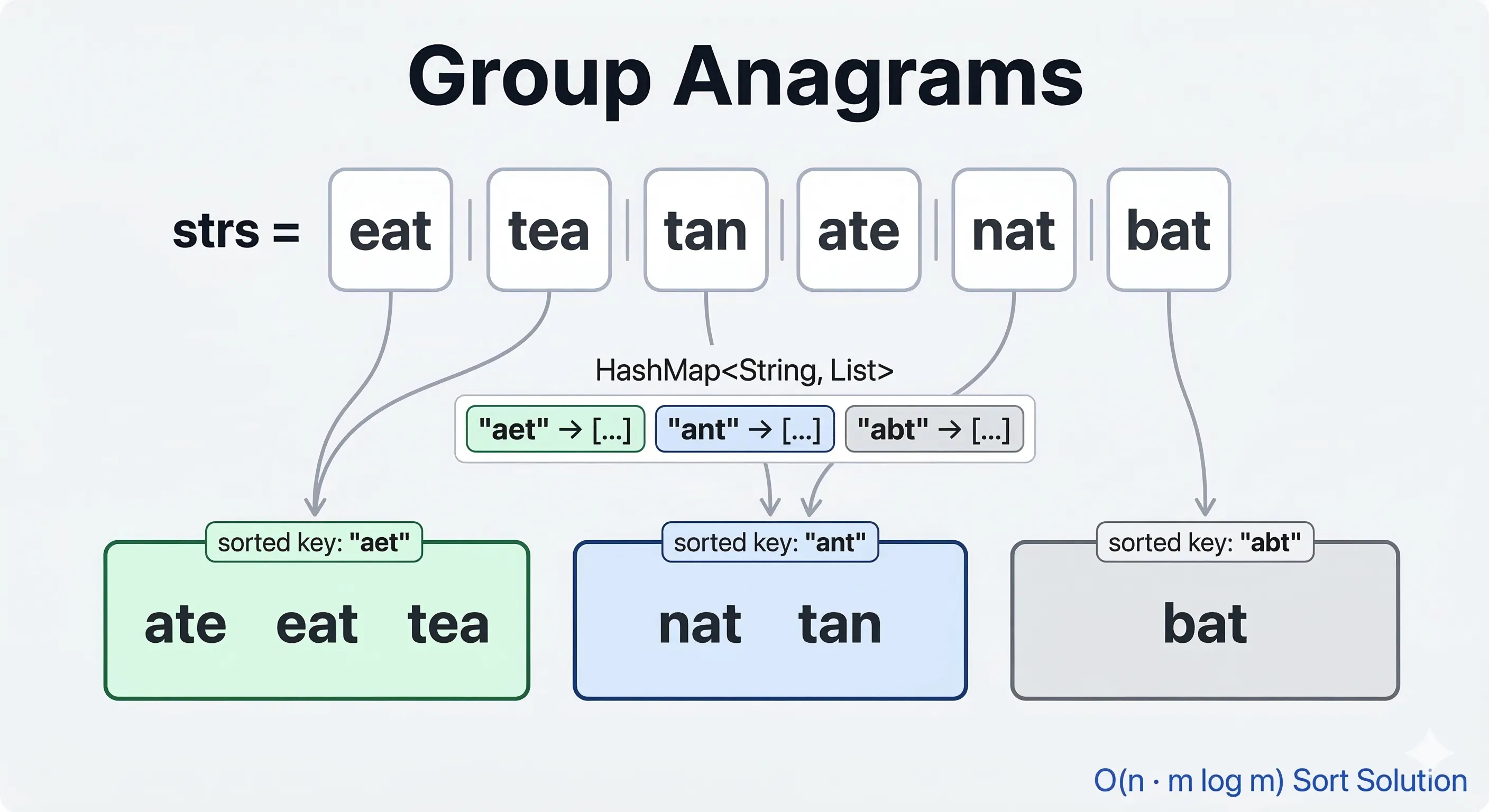
Input: strs = ["eat","tea","tan","ate","nat","bat"]
Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
natandtanare anagramsate,eatandteaare anagrams- There is no anagram for
batin the array
If you dont know how to find anagrams then refer this Valid Anagrams
Brute Force
Intuition
- We need to pick one string and using it, iterate over the other strings
- We need to check whether the character frequencies of the other string match the selected string
Code
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
int n = strs.size();
vector<vector<string>> result;
vector<int> isGrouped(n, 0);
for (int i = 0; i < n; i++) {
if (isGrouped[i] == 1)
continue;
vector<int> freq(26, 0);
string temp = strs[i];
for (auto it : temp) {
freq[it - 'a']++;
}
vector<string> group;
for (int j = i; j < n; j++) {
if (temp.size() != strs[j].size()) continue;
bool flag = isAnagram(strs[j], freq);
if (flag == true) {
group.push_back(strs[j]);
isGrouped[j] = 1;
}
}
result.push_back(group);
}
return result;
}
bool isAnagram(string str, vector<int> freq) {
for (char c : str) {
if (--freq[c - 'a'] < 0) {
return false;
}
}
return true;
}
};
Time and Space Complexity
- Time — O(n² · m) — for each of the
nstrings, we compare againstnothers, and each comparison scans up tomcharacters - Space — O(n) — for the
isGroupedarray
Why It Fails
- For every string, we’re comparing it against all other strings character by character
- This takes O(n² · m) time — too slow for large inputs
- We’re repeatedly scanning strings instead of using a smarter key to group them
Optimization
Intuition
- If two strings are anagrams, sorting them gives the same string — we can use that sorted string as a key to group them
Code
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> mp;
for (auto it : strs) {
string key = it;
sort(key.begin(), key.end());
mp[key].push_back(it);
}
vector<vector<string>> result;
for (auto& [key, group] : mp) {
result.push_back(group);
}
return result;
}
};
Time and Space Complexity
- Time — O(n · m log m) — we iterate over all
nstrings, and sorting each string of lengthmtakesm log m - Space — O(n · m) — for storing all strings in the hashmap
Key Takeaways
- Sometimes a small observation can lead you straight to the solution — like the fact that sorted anagrams are always identical strings